Eye-Con Server 코드분석
작성자 : 정지성
본 자료는 POSCO AI Big data Academy 프로젝트 Eye-Con 코드 분석 자료입니다.
소스코드는 https://github.com/jisung0920/EyeCon-Server 에서 볼 수 있습니다.
Eye-Con 소개 영상
eye-con 서버는 3개의 python 파일로 실행이 됩니다.
- run.py : 파라미터 설정, 서버를 실행하고 각 단계별로 작업을 수행합니다.
- econ.py : 각 단계별로 필요한 함수가 정의되어 있습니다.
- eyeconModel.py : 모델 관련 함수와 모델 클래스가 정의되어 있습니다.
프로그램 실행 순서로(run.py) 코드분석을 하겠습니다.
큰 흐름은 다음과 같습니다.
- 초기화
- 서버 실행
- 이미지 수신
- Gaze Tracking
- Gaze Classification
- Gaze Ratio
- Face Point
- Blink Detection
- Estimate expression
- 좌표 계산
- 데이터 전송
- 이미지 출력
초기화
초기화 단계에서는 인자(argument)를 받고 계산에 필요한 변수와 함수를 설정합니다.
IMG_WIDTH , IMG_HEIGHT= 480, 640
ANRD_WIDTH,ANRD_HEIGHT = 1170,1780
수신 받는 이미지의 가로, 세로 크기와
안드로이드 기기의 가로, 세로 크기를 명시합니다.
이 변수들은 이후 좌표를 계산하는데 사용됩니다.
emotion_dict = {0: "neutral", 1: "happiness", 2: "surprise", 3: "sadness", 4: "anger",
5: "disgust", 6: "fear", 7: "comtempt", 8: "unknown", 9: "Not a Face"}
표정에 관한 값을 설정합니다.
FER 모델의 출력은 int 로 나옵니다.
출력값과 매칭되는 표정을 텍스트로 정리한 것입니다.
parser = argparse.ArgumentParser()
parser.add_argument('--util_path',default='./utils/',required = False, help='util file path')
parser.add_argument('--blink_th',default=0.25,required=False, help='eye blick value threshold')
parser.add_argument('--ip',default='192.168.0.25')
parser.add_argument('--port',default=8200,type=int)
args = parser.parse_args()
util_path = args.util_path
IP,PORT = args.ip, args.port
BLINK_TH = args.blink_th
프로그램 실행 시 입력한 인자를 받아옵니다.
예를 들어
$ python run.py --ip 192.168.0.21
와 같이 실행하면
IP 값이 192.168.0.21 로 설정됩니다.
입력하지 않는 경우 default 로 정의된 값으로 설정됩니다.
util_path 의 경우 랜드마크나 얼굴 분류 파일이 들어있는 파일 명을 써야합니다.
blink_th 은 눈을 감았다고 처리하는 임계값을 의미합니다. 낮을수록 감았다고 처리하는 것이 어려워집니다.
ip 는 현재 자신의 ip 로 설정합니다. ifconfig나 ipconfig 명령어로 확인할 수 있습니다.
port 번호는 실행 시 포트가 막혀있는 경우 다른 번호로 설정하면 됩니다.
parser 클래스의 parse_args() 로 아규먼트 객체를 받아오고
args.ip 와 같은 방식으로 아규먼트 값을 받아올 수 있습니다.
faceClassifier = econ.loadClassifier(util_path)
predictor = dlib.shape_predictor(util_path + 'shape_predictor_68_face_landmarks.dat')
detector = dlib.get_frontal_face_detector()
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
파일로 부터 얼굴 분류기와 얼굴의 랜드마크를 예측하는 predictor, detector 를 설정합니다.

cv2의 CascadeCalssifier 함수를 사용합니다.
Xml 파일은 분류기 파일입니다. 여기서 받을 수 있습니다.
dlib을 사용하여 랜드마크관련 객체들을 받아옵니다.
얼굴 랜드마크에 필요한 파일은 여기서 받을 수 있습니다.
(lStart, lEnd) 는 랜드마크에서 눈의 index 를 의미합니다. (36,41)

prev_x, prev_y = ANRD_WIDTH/2, ANRD_HEIGHT/2
momentum = 0.7
초기 좌표값을 설정합니다.
아무값이나 괜찮지만 모멘텀을 넣었으므로
중간값으로 설정하였습니다.
device = torch.device('cpu')
Gaze_model, FER_model = GazeModel(),FERModel()
Gaze_model.eval()
모델 실행 시 cpu 디바이스를 사용한다는 것을 명시하기 위해 설정합니다.
Gaze 모델과 FER 모델을 불러옵니다.
초기화 시 자동으로 학습된 모델을 불러오도록 만들었습니다.
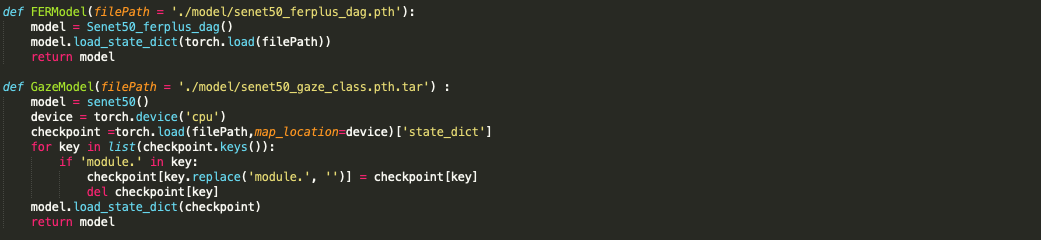
econModel.py 에 정의되어 있습니다.
model 폴더 안에 학습된 모델 파일들(pth) 이 있어야 합니다.
GazeModel 에서 replace 를 한 이유는
모델의 변수(컨볼루션레이어의 이름) 에 앞에 module. 이 붙어있어서 지우기 위함입니다.
load_stat_dict 내장 함수를 사용하여 weight bias 값들을 불러와서 설정할 수 있습니다.
train이 아니므로 .eval()을 사용합니다.
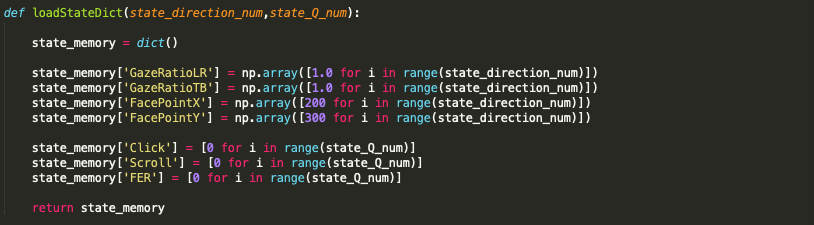
state_direction_num = 5
state_Q_num = 3
state_memory = econ.loadStateDict(state_direction_num,state_Q_num)
eyecon에서 표정, Blink를 판별하거나 좌표를 계산할 때
노이즈로 들어온 값의 영향을 줄이기 위해
이전값들을 사용합니다.
이전값들은 특정 크기만큼의 배열을 생성하여 저장합니다.
배열의 평균값이나 최빈값 등을 사용하여 노이즈를 처리합니다.
state_direction_num, state_Q_num 는 배열의 크기(저장할 이전값의 수) 를 의미합니다.
서버 실행
서버는 TCP 프로토콜을 사용합니다.
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((IP, PORT))
server_socket.listen()
TCP 소켓을 생성하고 (socket.socket(socket.AF_INET, socket.SOCK_STREAM))
IP와 Port 번호로 소켓을 연결합니다.
다른 디바이스에서 연결이 될 때까지 기다립니다. (server_socket.listen())
try:
client_socket, addr = server_socket.accept()
print('Connected with ', addr)
count = 0
while True:
...
count += 1
except Exception as e:
print('Connecting Error')
finally:
print('End of the session')
서버와 디바이스가 연결된 경우 try 내부의 코드가 실행됩니다.
우선 클라이언트(디바이스)의 소켓과 주소를 받아옵니다.
클라이언트에게 좌표를 보내줘야하기 때문에 소켓이 필요합니다.
이전값들을 사용하기 위해 count 를 두어 사용합니다.
> state_memory['FacePointX'][count % 3]
이와 같은 식으로 3번째전에 받아온 값을 저장, 사용할 수 있습니다.
While 문을 통해 서버와 클라이언트간 통신이 계속해서 수행됩니다.
통신 중 문제가 발생할 경우 except 문이 실행됩니다.
이미지 수신
length = econ.recvAll(client_socket, 10)
frame_bytes = econ.recvAll(client_socket, int(length))
image = cv2.imdecode(np.frombuffer(frame_bytes, np.uint8), cv2.IMREAD_COLOR)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
클라이언트로부터 데이터를 수신합니다.
처음 10byte는 데이터의 크기를 나타내고 이후 데이터는 이미지(프레임)를 나타냅니다.
데이터의 크기를 알아야 수신할 수 있으므로
우선 크기 정보를 파악하고
데이터(이미지) 를 수신합니다.

바이트 형태로 들어온 데이터를 np.uint8 형태로 변환합니다.
이미지로 처리하기 위함입니다.
일부 작업에서는 gray scale로 처리하기 때문에 미리 gray 형식도 만들어 줍니다.
Gaze Tracking
Gaze tracking은 classification / gaze ratio / face point 의 작업을 단계별로 수행합니다.
Gaze Classification
inputData = Image.fromarray(image)
inputData = transformImg(inputData)
x,y = econ.getGazePoint(Gaze_model,inputData,ANRD_WIDTH,ANRD_HEIGHT)
이미지를 모델의 입력으로 넣을 수 있도록 변환합니다.

이미지의 크기를 조절하고, 텐서로 바꾸고, 채널 별로 정규화를 수행합니다.
모델의 결과를 가지고 디바이스 크기에 맞춰서 x,y 좌표를 가져옵니다.
분류 결과의 확률값을 사용하였습니다.
기존 분류모델을 구역별 16개의 class를 구분하였습니다.
현재 필요한 것은 4분할 class 입니다. (학습할 시간이 없어서 16분할 모델을 그대로 사용하였습니다.)
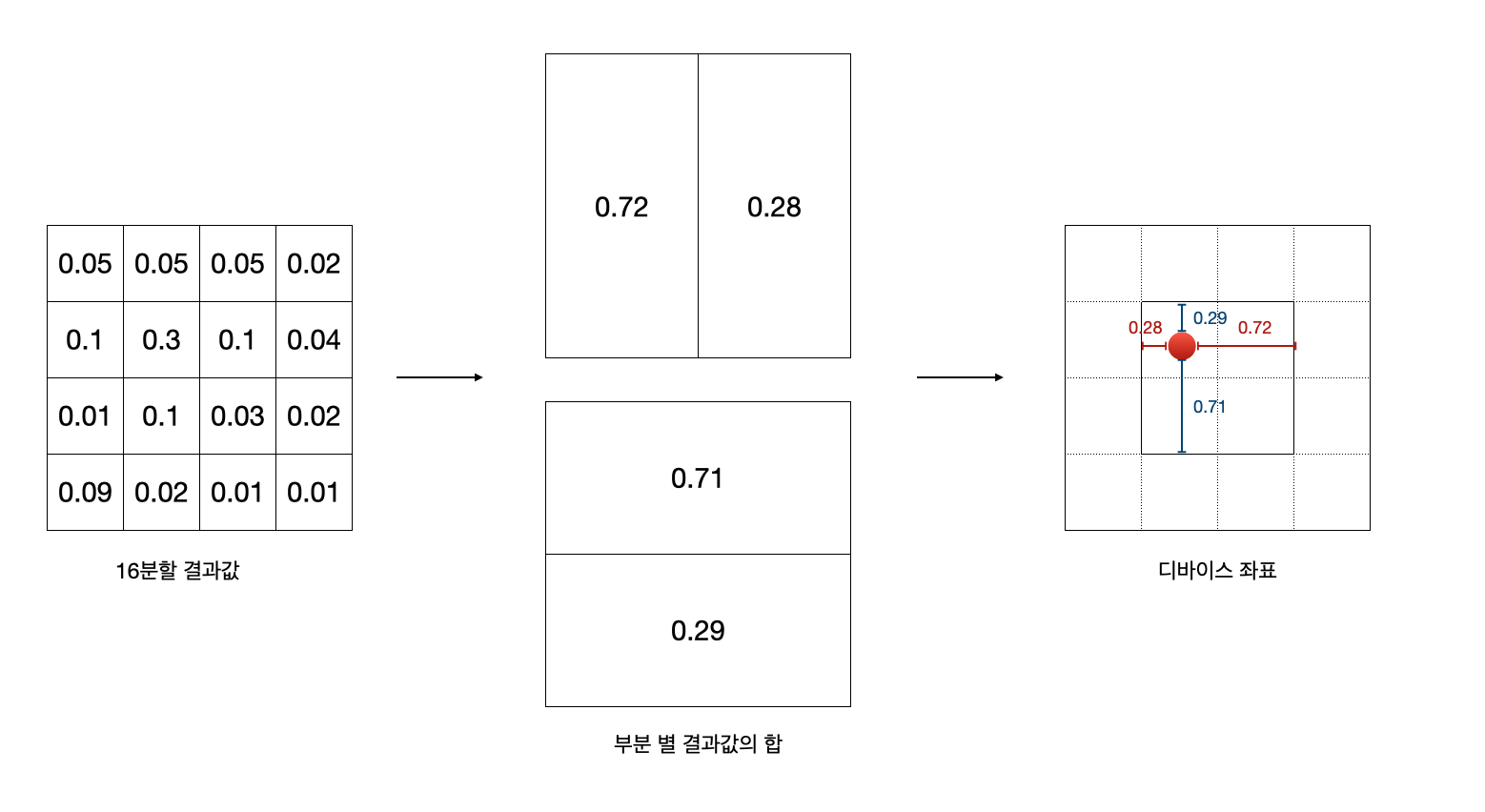
16분할의 값을 가로 세로 2분할의 값으로 변환을 하고
디바이스에 맞춰 비율로 값을 산출합니다.
상하좌의 1/4 씩 패딩을 주었습니다.
만약 상단 좌우의 값이 1과 0 이라면 (0.72/0.28)
x좌표는 디바이스의 1/4 지점에 위치하게 됩니다.

Gaze Ratio
rects = detector(gray, 0)
for rect in rects:
faceLandmark = predictor(gray, rect)
if(len(rects) != 0) :
horizontal_gaze_ratio_left_eye, vertical_gaze_ratio_left_eye =
econ.getGazeRatio(gray, faceLandmark,np.arange(lStart,lEnd+1))
horizontal_gaze_ratio_right_eye, vertical_gaze_ratio_right_eye =
econ.getGazeRatio(gray, faceLandmark,np.arange(rStart,rEnd+1))
horizontal_gaze_ratio = (horizontal_gaze_ratio_right_eye +
horizontal_gaze_ratio_left_eye) / 2
vertical_gaze_ratio = (vertical_gaze_ratio_right_eye + vertical_gaze_ratio_left_eye) / 2
state_memory['GazeRatioLR'][count % state_direction_num] = horizontal_gaze_ratio
state_memory['GazeRatioTB'][count % state_direction_num] = vertical_gaze_ratio
gazeRatioLR = horizontal_gaze_ratio - state_memory['GazeRatioLR'].mean()
gazeRatioTB = vertical_gaze_ratio - state_memory['GazeRatioTB'].mean()
else :
state_memory['GazeRatioLR'][(count) % state_direction_num] = 1
state_memory['GazeRatioTB'][(count) % state_direction_num] = 1
gazeRatioLR = state_memory['GazeRatioLR'][(count) % state_direction_num] -
state_memory['GazeRatioLR'].mean()
gazeRatioTB = state_memory['GazeRatioTB'][(count) % state_direction_num] -
state_memory['GazeRatioTB'].mean()
우선 detector로 이미지에서 사람의 얼굴을 찾습니다.
predictor 로 각 얼굴의 랜드마크를 찾을 수 있습니다.
현재 얼굴 하나만 고려하기 때문에 for문의 마지막 얼굴의 랜드마크만 고려합니다.
getGazeRatio 함수를 사용하여 왼쪽, 오른쪽 눈의 gaze ratio 를 파악합니다.(상하좌우)
왼쪽 부분의 흰색과 오른쪽 부분의 흰색의 비율을 사용합니다.
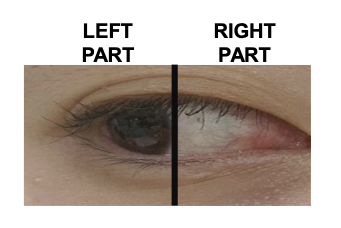
얻은 ratio 값은 state_memory 에 저장을 합니다.
이전 프레임과 차이를 통해 왼쪽으로 이동했는지 오른쪽으로 이동했는지 파악할 수 있습니다. (상하도 동일한 방식으로)
왼쪽으로 간다면 음수, 오른쪽으로 간다면 양수가 나오게 됩니다.
만약 바로 이전 데이터에 노이즈가 있다면 잘못된 값이 나오게 됩니다.
때문에 초기화 단계에서 정의한 state_memory 를 사용합니다.
바로 직전의 데이터만 보는 것이 아니라
최근 몇개의 데이터를 같이 봐서 노이즈의 영향을 줄여줍니다.
위해 현재 얻은 값에 이전 값들의 평균을 빼는 방식으로 구현을 하였습니다.
만약 얼굴을 찾지 못한 경우(else)는
값을 1로 설정해줍니다.
값 1은 중앙에 있다는 것을 의미합니다.
gaze ratio 구하는 방식은 여기서 알 수 있습니다.
Face Point
facePoints = faceClassifier.detectMultiScale(image,1.2,cv2.COLOR_BGR2GRAY)
if(len(facePoints)!= 0 ) :
faceX,faceY = econ.getFaceXY(facePoints)
state_memory['FacePointX'][count % state_direction_num],\
state_memory['FacePointY'][count % state_direction_num] = faceX,faceY
else :
state_memory['FacePointX'][count % state_direction_num] = state_memory['FacePointX'][(count-1) % state_direction_num]
state_memory['FacePointY'][count % state_direction_num] = state_memory['FacePointY'][(count-1) % state_direction_num]
faceDirectionX = (state_memory['FacePointX'][count%state_direction_num] - state_memory['FacePointX'].mean())/IMG_WIDTH
faceDirectionY = (state_memory['FacePointY'][count%state_direction_num] - state_memory['FacePointY'].mean())/IMG_HEIGHT
얼굴의 중앙점을 찾습니다.
이전에 파일을 통해 불러온 classifier 를 사용하여
얼굴들의 (x,y,w,h) 정보가 있는 facePoints 변수를 만듭니다.
getFaceXY 함수를 사용하여 얼굴의 중앙점 좌표를 가져옵니다.

x = 얼굴 사각형의 x좌표 + (얼굴 사각형의 너비/2)
y = 얼굴 사각형의 y좌표 + (얼굴 사각형의 높이/2)
여러 얼굴이 facePoints에 있을 수 있으므로
그중 첫번째 얼굴만(faceImage[0]) 만 사용하였습니다.
Blink Detection
if(len(rects) != 0 ) :
eyeLandmark = face_utils.shape_to_np(faceLandmark)
if(econ.isBlink(eyeLandmark,BLINK_TH,lStart,lEnd)) :
state_memory['Click'][count%state_Q_num] = 0
else :
state_memory['Click'][count % state_Q_num] = 1
if(econ.isBlink(eyeLandmark,BLINK_TH,rStart,rEnd)) :
state_memory['Scroll'][count % state_Q_num] = 0
else :
state_memory['Scroll'][count % state_Q_num] = 1
else :
state_memory['Click'][count % state_Q_num] =0
state_memory['Scroll'][count % state_Q_num] =0
isBlink 함수를 사용하여 눈이 안감긴 경우 0, 눈을 감은 경우 1 로 처리를 합니다.
노이즈 처리를 위해 state_memory 을 사용합니다 .

isBlink 함수는
눈의 랜드마크 좌표를 활용합니다.
눈의 EAR 를 구하고 그 값이 임계값(blink_th) 보다
높으면 눈을 뜬 것이고(True), 낮으면 감은 것 입니다(False).
EAR 은 눈의 수평선과 수직선의 비율을 사용하여 구합니다.
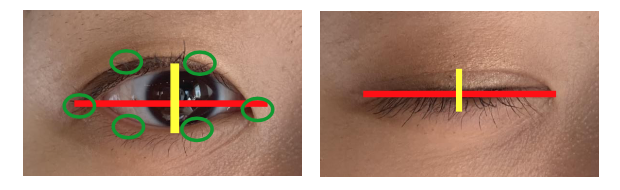

왼쪽 눈은 click, 오른쪽 눈은 scroll 입니다.
Estimate expression
state_memory['FER'][count%state_Q_num], tagPosition = econ.getExpression(facePoints,image,FER_model)
FER 모델을 사용하여 얼굴의 표정과 얼굴 상단의 x,y 좌표(태그 입력용) 를 가져옵니다.

흑백이미지를 사용합니다.
이미지에서 얼굴만 잘라서 사용합니다.
모델에 사용할 수 있도록 이미지의 크기를 조정하고 정규화, 변환을 합니다.
모델을 사용하고 결과의 max 인자를 찾습니다.
(분류모델이므로 가장 높은 확률을 가진 인자를 찾는다.)
좌표 계산
click = econ.modeList(state_memory['Click'])
scroll = econ.modeList(state_memory['Scroll'])
if (click == 1 or scroll == 1):
FERNum = 0
tagPosition = (0, 0)
else:
FERNum = econ.modeList(state_memory['FER'])
cv2.putText(image,emotion_dict[FERNum],tagPosition, cv2.FONT_HERSHEY_SIMPLEX, 0.8,(0, 255, 0), 1, cv2.LINE_AA)
d1_x, d1_y = econ.rateToDistance(gazeRatioLR,gazeRatioTB,ANRD_WIDTH,ANRD_HEIGHT,weight=0.5)
d2_x, d2_y = econ.rateToDistance(faceDirectionX, faceDirectionY, ANRD_WIDTH,ANRD_HEIGHT,weight=0.5)
x += d1_x + d2_x
y += d1_y + d2_y
x, y =int(x*momentum + prev_x * (1-momentum)) , int(y*momentum + prev_y * (1-momentum))
prev_x, prev_y = x, y
클라이언트에게 보낼 데이터를 처리합니다.
click과 scroll 은 최근의 값 중 최빈값 (modeList) 을 사용합니다.

click이나 scroll 이 있는 경우 표정인식은 하지 않습니다. (인식이 잘못될 가능성 높음)
rateToDistance 함수를 사용하여
Gaze ratio, face point 에서 이동한 비율을
실제 디바이스의 거리에 맞게 조정해 줍니다.

Weight 값을 조절하여 어느정도 늘릴지 선택할 수 있습니다.
gaze classification 모델에서 얻은 좌표에
rateToDistance로 얻은 값을 더해줍니다.\((x += d1_x + d2_x)\)
momentum을 사용해 값을 조정하고
산출한 값을 저장합니다.
데이터 전송
cord = str(x) + '/' + str(y) + '/' +str(click) + '/' + str(scroll) + '/' + str(FERNum)
print(cord)
client_socket.sendall(bytes(cord,'utf8'))
처리한 데이터들을 ‘/’ 으로 구분지어 문자열을 만들고
클라이언트에게 보내줍니다.
문자열로 만든 이유는 편의성 때문입니다.
다른 방식이 더 효율적일 수 있습니다.
이미지 출력
for (x,y,w,h) in facePoints:
cv2.rectangle(image,(x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow('Android Screen', image)
count += 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
수신한 이미지 데이터를 서버 화면에 띄워줍니다.
얼굴에는 rectangle 함수를 사용하여 네모 칸을 그려줍니다.
‘q’키를 눌러 종료할 수 있습니다.
Comments