Web and Graph
해당 포스팅은 스탠포드의 Jure Leskovec 교수님의 강의 와 Mining of Massive Datasets(Jure Leskovec, Anand Rajaraman, Jeff Ullman) 책 을 참고하였습니다.
현재 웹페이지는 수십억개가 있습니다.
이 많은 웹페이지 중에는 스팸페이지도 많고, 신뢰도가 없는 페이지들도 많습니다.
그렇기 때문에 웹 검색을 할 때 사용자들이 원하고, 신뢰할 수 있을만한 페이지를 보여주는 것이 필요합니다.
페이지랭크(=PageRank)란 웹에 있는 각 페이지에게 숫자를 할당하는 일종의 함수입니다.
이 숫자가 높을수록 페이지가 중요(important) 하다는 것을 나타내도록 함수를 구성해야합니다.
페이지랭크 알고리즘은 하나의 특정한 알고리즘이 있는 것은 아니며, 기본 개념에 기반하여 여러 형태로 구성할 수 있습니다.
웹의 구조는 방향 그래프(=directed graph) 로 볼 수 있습니다.
웹 구조에서, 페이지(=page)는 노드(=node)이고 페이지($p_1$)에서 다른 페이지($p_2$)로 갈 수 있는 링크를 그래프에서의 엣지(=edge)로 볼 수 있습니다.
아래 그림은
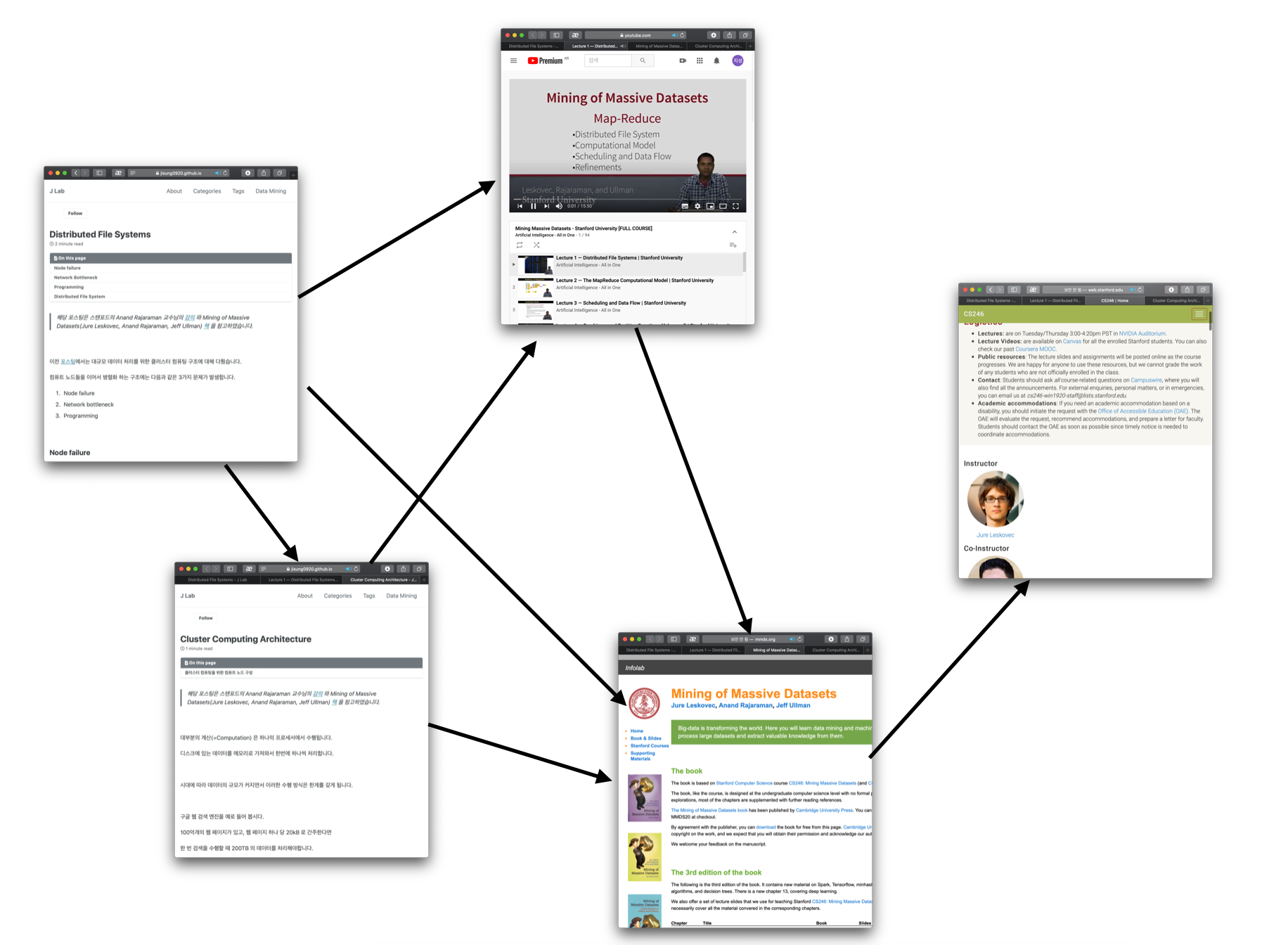
이러한 그래프로 표현 할 수 있습니다.
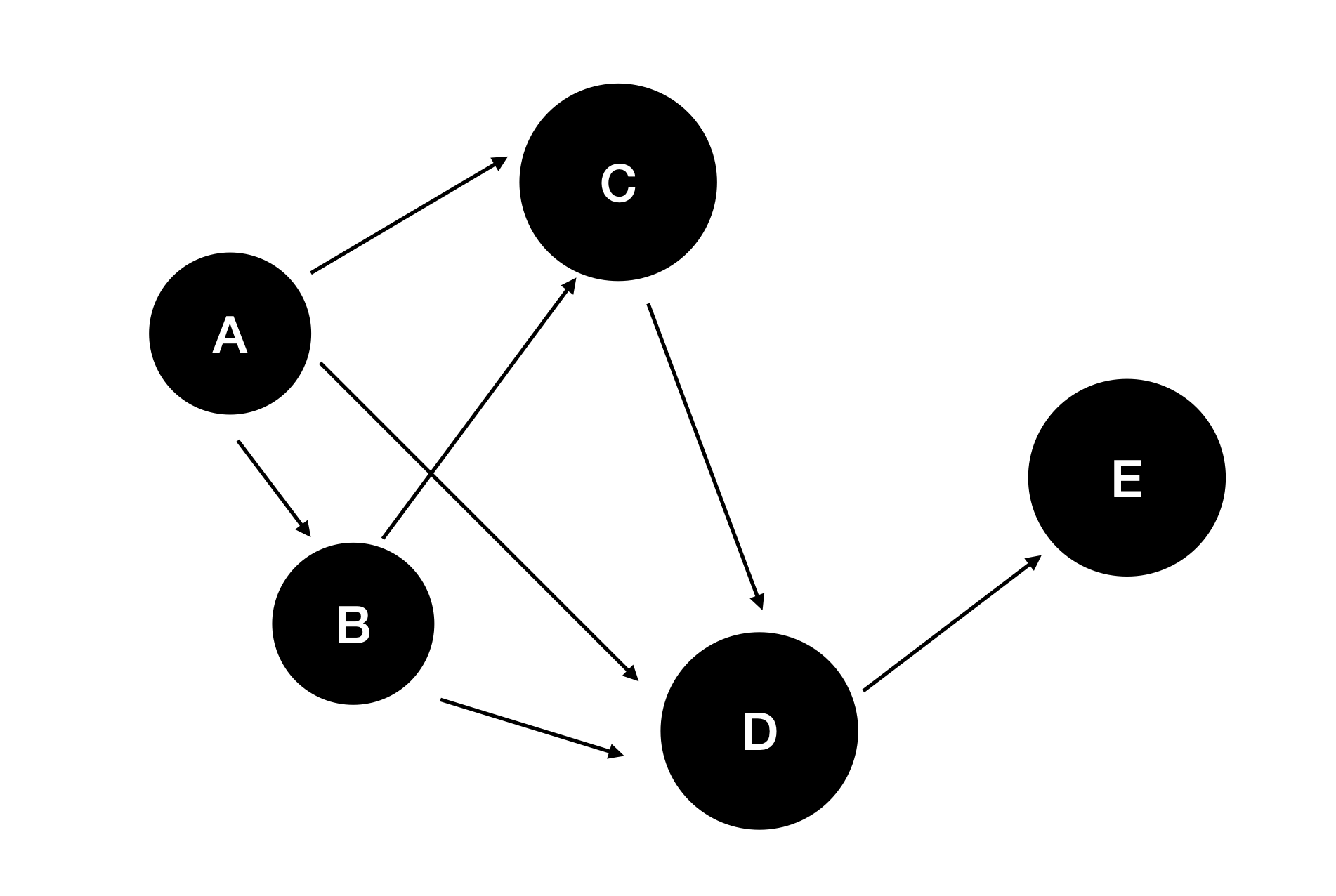
이런식으로 웹 구조를 그래프의 형태로 볼 수 있습니다.
이렇게 웹 페이지의 중요도를 찾는 문제는
그래프 구조에서 노드의 중요도를 찾는 문제로 변환할 수 있습니다. (Link Analysis)
때문에 여기서 사용하는 방식들을 다른 문제들에도 적용을 할 수 있습니다.
예를 들어 SNS에서 사람(노드)과 팔로우(엣지) 와 같은 형태로 적용해 볼 수 있습니다.
이번 페이지랭크 모듈 포스팅에서는,
페이지랭크의 기본 컨셉에 대해서 설명하고,
발생할 수 있는 문제 상황과 해결방법,
실제 사용하는 페이지랭크에 대해 다뤄보겠습니다.
Comments