MapReduce (Advanced)
해당 포스팅은 스탠포드의 Anand Rajaraman 교수님의 강의 와 Mining of Massive Datasets(Jure Leskovec, Anand Rajaraman, Jeff Ullman) 책 을 참고하였습니다.
지난 포스팅에서 MapReduce 의 기본 동작에 대해 알아보았습니다.
이번 포스팅에서는 좀 더 세부적인 사항과 부가적인 내용을 다룹니다.
Details of MapReduce Excecution
맵리듀스 시스템의 시작은 fork 로 부터 시작됩니다.
사용자 프로그램(User program)은 fork 하여 하나의 Master 와 여러개의 worker 로 복제됩니다.
마스터는 worker에게 Map 을 할지 Reduce를 할지 지정해줍니다. (지정이 안될 수 도 있습니다.)
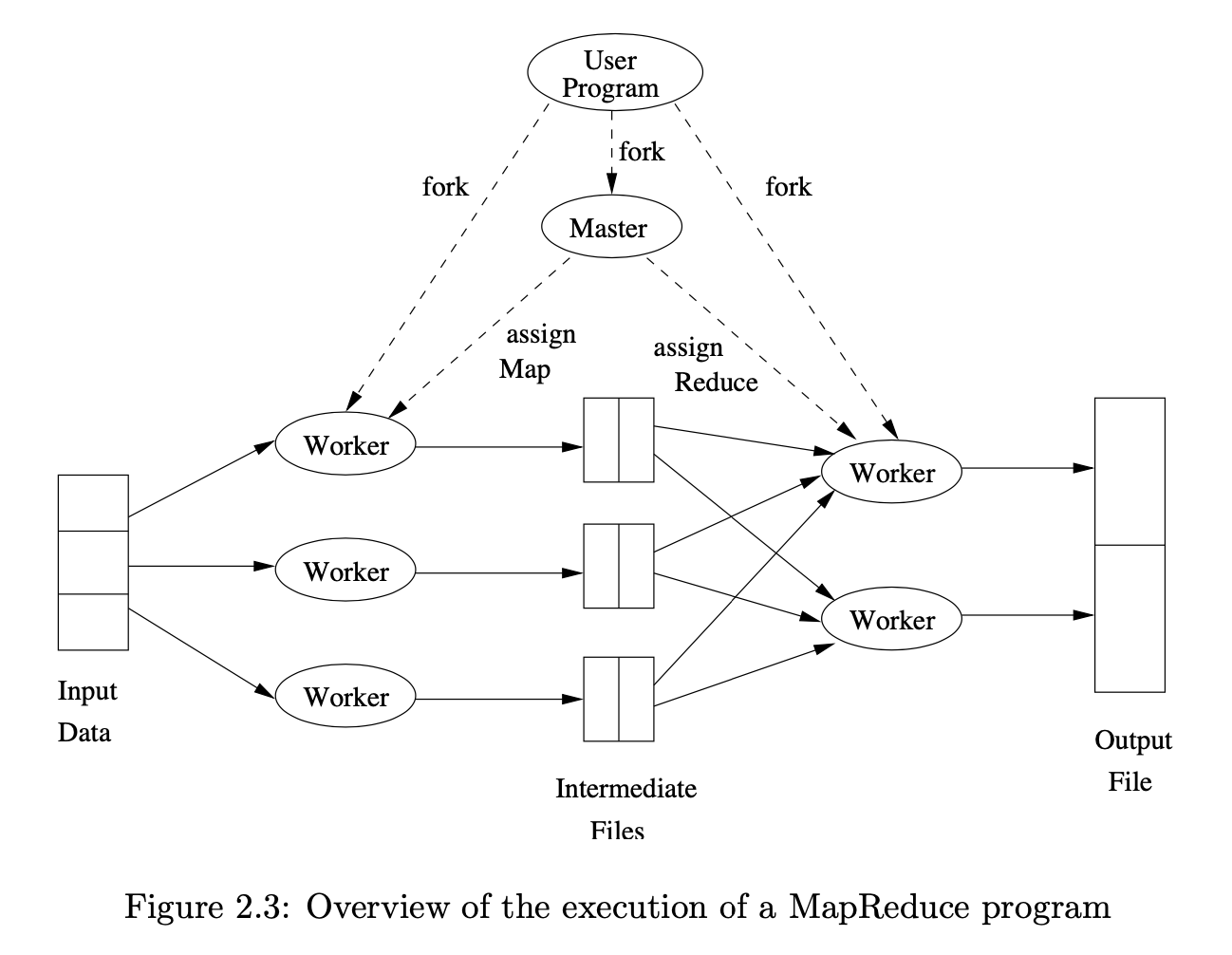
이미지 출처 : Mining of Massive Datasets - Figure 2.3
여기서 맵, 리듀스 워커의 수는 사용자가 임의로 정할 수 있습니다.
일반적으로 맵은 각 청크마다 하나씩 정하는 것이 효율적입니다. (하나의 노드에 하나의 테스크)
리듀스는 맵 워커보다는 적게 만드는 것이 일반적입니다.
리듀스 워커의 수만큼 중간파일(intermediate file)이 생성됩니다. 중간 파일이 많아지면 read 작업이 더 많이 필요하게 되며 Map 작업으로 얻은 효율이 떨어지게 됩니다.
맵과 리듀스의 테스크는 3가지 상태를 갖습니다. idle, excuting, completed.
마스터 프로세스는 모든 테스크의 상태를 파악하고 있으며, 워커 프로세스들은 작업이 끝나게 되면 마스터에게 보고를 합니다.
각 맵 테스크는 사용자에 의해 작성된 Map function에 의해 실행됩니다.
맵 테스크는 각 리듀스 테스크를 위한 파일을 만들어 맵 테스크를 하고 있는 워커의(노드의) 로컬 디스크에 저장합니다.
마스터는 이 파일의 크기와 위치를 알고있고, 어느 리듀스 테스크로 가야하는지에 대해 알려줍니다.
마스터가 워커 프로세스에게 리듀스 테스크를 할당할 때, 그 테스크는 중간 파일을 입력의 형태로 받습니다.
리듀스 테스크는 사용자에 의해 작성된 Reduce function에 의해 실행됩니다.
그리고 테스크의 출력을 DFS의 형태로 저장(write)합니다.
Node failure
MapReduce 에서는 컴퓨트 노드의 역할에 따라 Master, Map Worker, Reduce Worker 3가지로 분류되고,
노드에 문제가 발생하는 경우 종류 별로 다르게 대처합니다.
Master
마스터가 있는 노드에 문제가 발생한 경우는 모든 맵리듀스 작업을 중단해야합니다. 맵리듀스 시스템에서 발생할 수 있는 최악의 상황이지만, 발생할 확률은 매우 낮습니다.
Map Worker
맵 워커가 있는 노드에서 문제가 발생하면
해당 노드의 모든 맵 테스크들은 전부 다시 작업을 수행해야 합니다. 문제 발생 이전에 완료한 테스크도 재시작을 해야합니다.
완료된 작업도 다시 수행하는 이유는 중간 파일의 위치 때문입니다.
맵 워커가 만들어질 때 리듀스 워커도 만들어 집니다.
리듀스 워커는 맵 작업이 완료되기 전부터 중간 파일의 위치를 알고 있습니다.
맵 노드에 문제가 발생하면 해당 노드에서 만드는 중간 파일을 완성하지 못하게 되어 리듀스 작업에 사용할 수 없습니다.
마스터는 주기적으로 워커에 핑을 쏴 문제가 발생하는지 확인할 수 있습니다.
마스터는 문제가 있는 노드에 있는 맵 작업들을 idle 로 설정합니다. 그리고 동작이 가능한 워커에게 스케줄합니다.
해당 작업이 다른 워커에게 할당되면 마스터는 그 위치를 리듀스 워커에게 알려줍니다. (중간 파일 위치를 알아야 하므로)
Reduce
단순하게 처리할 수 있습니다. 현재 실행하고 있는 리듀스 테스크의 상태를 idle 로 바꾸면 됩니다. 다른 워커에게 해당 테스크가 할당됩니다.
Combiners
리듀스 함수가 교환법칙(commutative) 과 결합법칙(associative)이 성립하는 경우가 있습니다.
이 경우 결합된 벨류들은 어떠한 순서로든 동일한 결과가 나오게 결합될 수 있습니다.
워드 카운팅의 경우 순서를 어떻게 하는지나 벨류들의 리스트 수를 어떻게 그룹짓는지 상관없이 동일한 결과가 나옵니다.
리듀스 함수가 교환,결합이 성립할 때,
리듀서가 하는 작업의 일부를 맵 테스크에서 수행시켜서 리듀스 테스크의 부하를 줄일 수 있습니다.
워드 카운트에서는 각 맵 테스크는 $(w,1) ,(w,1) …$ 쌍을 많이 생성합니다.
여기서 맵 테스크의 출력들이 합쳐지기 전에,
다음과 같이, 각 맵 테스크안에서 리듀스 작업(Combiner)를 수행해 줍니다.
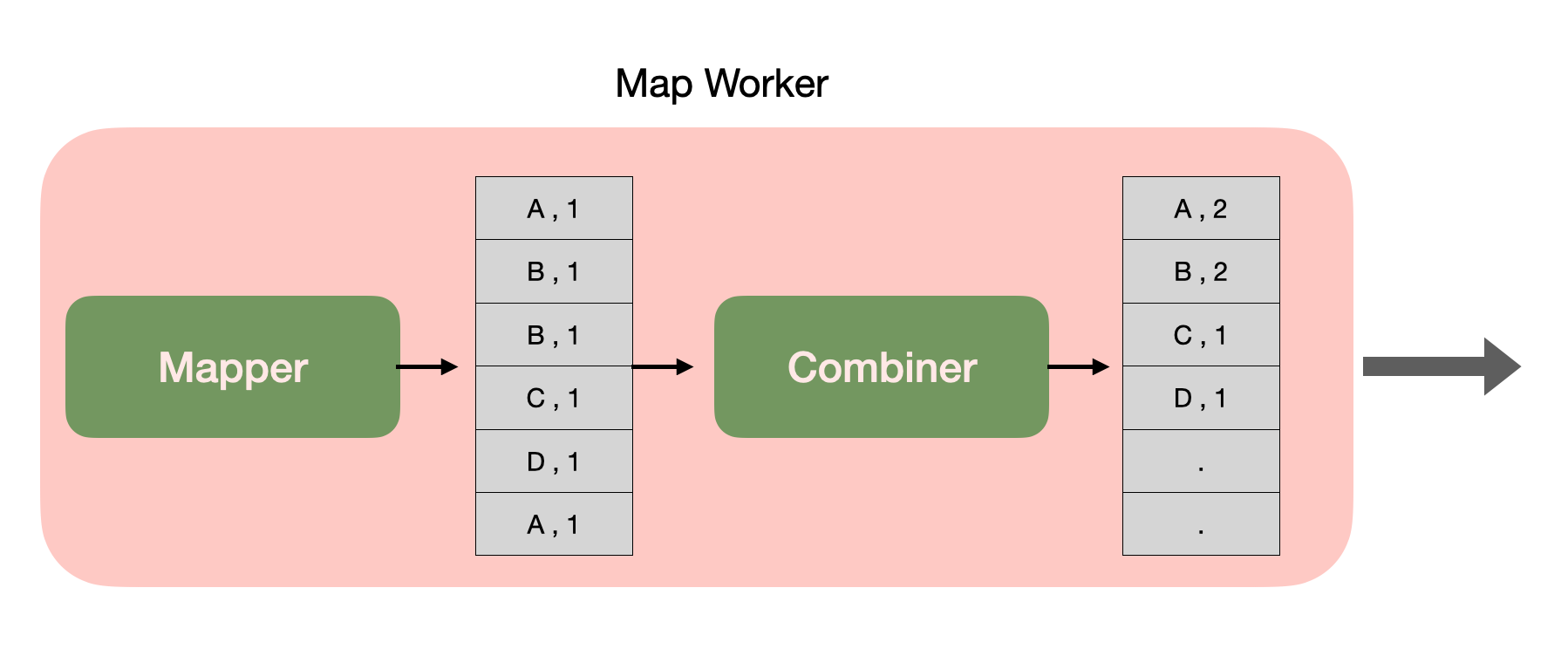
이런 방식이 작업에 도움이 되는 이유는, 맵 워커와 리듀스 워커 수의 차이 때문입니다.
리듀스 워커는 중간파일의 파티션을 조정하는 등의 이유로 비교적 적은 수로 만들어집니다.
더 많은 수의 노드(맵 워커)에서 리듀스 작업을 미리 어느 정도 수행하므로 더 병렬적으로 처리할 수 있습니다.
Partition function
리듀서의 숫자 R 을 정하면 시스템에서 해쉬 함수를 맞춰서 만들어 줍니다. 그러나 이렇게 만들어진 해쉬 함수가 reduce 작업에 적절하게 분배되도록 보장하지는 못합니다. 예를 들어 영어 텍스트를 처리하고자 할 때 ‘the’ 나 ‘a’ 같은 단어의 빈도는 매우 높습니다. 이렇게 되면 특정 reduce 작업에 로드가 많아지게 됩니다.
이런 상황을 개선할 수 있도록 맵리듀스에서는 해쉬 함수 오버라이드를 지원합니다.
사용자가 원하는 해시함수를 정의하여 리듀스 작업을 균등하게 수행할 수 있도록 할 수 있습니다.
이 외에도 맵리듀스 관련 토픽들이 많습니다. 이에 대해서는 MMD 포스팅을 마친후에 정리해보고자 합니다.
Comments