MapReduce
해당 포스팅은 스탠포드의 Anand Rajaraman 교수님의 강의 와 Mining of Massive Datasets(Jure Leskovec, Anand Rajaraman, Jeff Ullman) 책 을 참고하였습니다.
이전 포스팅들을 정리해보자면,
대규모 데이터를 빠르게 처리하기 위해 병렬로 계산하는 방식을 고안하였습니다.
우선, 노드들을 스위치, 이더넷으로 연결하여 한번에 많은 연산을 수행할 수 있도록 물리적 구조를 만들었습니다.
이 구조에서는 Node failure, Network Bottleneck, Programming 문제가 발생하였고,
다음으로 Distributed File System 을 사용하여 Node failure 문제를 어느정도 해결할 수 있었습니다.
이번 포스팅에서는 대량의 데이터를 병렬적으로 처리할 수 있는 프로그래밍 시스템인 맵리듀스(=MapReduce) 에 대해 다룹니다.
이 시스템을 도입하면 Bottleneck 과 Programming 문제를 해결할 수 있습니다.
MapReduce
맵리듀스는 사용자가 임의로 맵 함수와 리듀스 함수를 구현하여 만듭니다.
이 두가지 함수만 구현하면 맵리듀스 시스템은 자체적으로 작업과 병렬 실행, 실패 케이스 등을 처리해줍니다.
이렇게 Programming 문제를 해결합니다.
또한 Worker 프로세스를 사용하여 파일의 청크가 있는 노드에서 작업을 수행하도록 합니다.
프로세스가 있는 곳으로 데이터를 옮긴다는 기존 발상 대신,
데이터 위치에 따라 프로세스를 맞춘다는 컨셉을 사용합니다.
이러한 방식으로 데이터 이동(move)을 줄여 Network Bottleneck 현상을 방지합니다.
맵리듀스는 크게
- Map
- Group by Key
- Reduce
세 단계로 나눠집니다.
우선 혼동할 수 있는 몇가지 용어들을 정리 한 후 각 단계별로 설명하겠습니다.
용어 정리
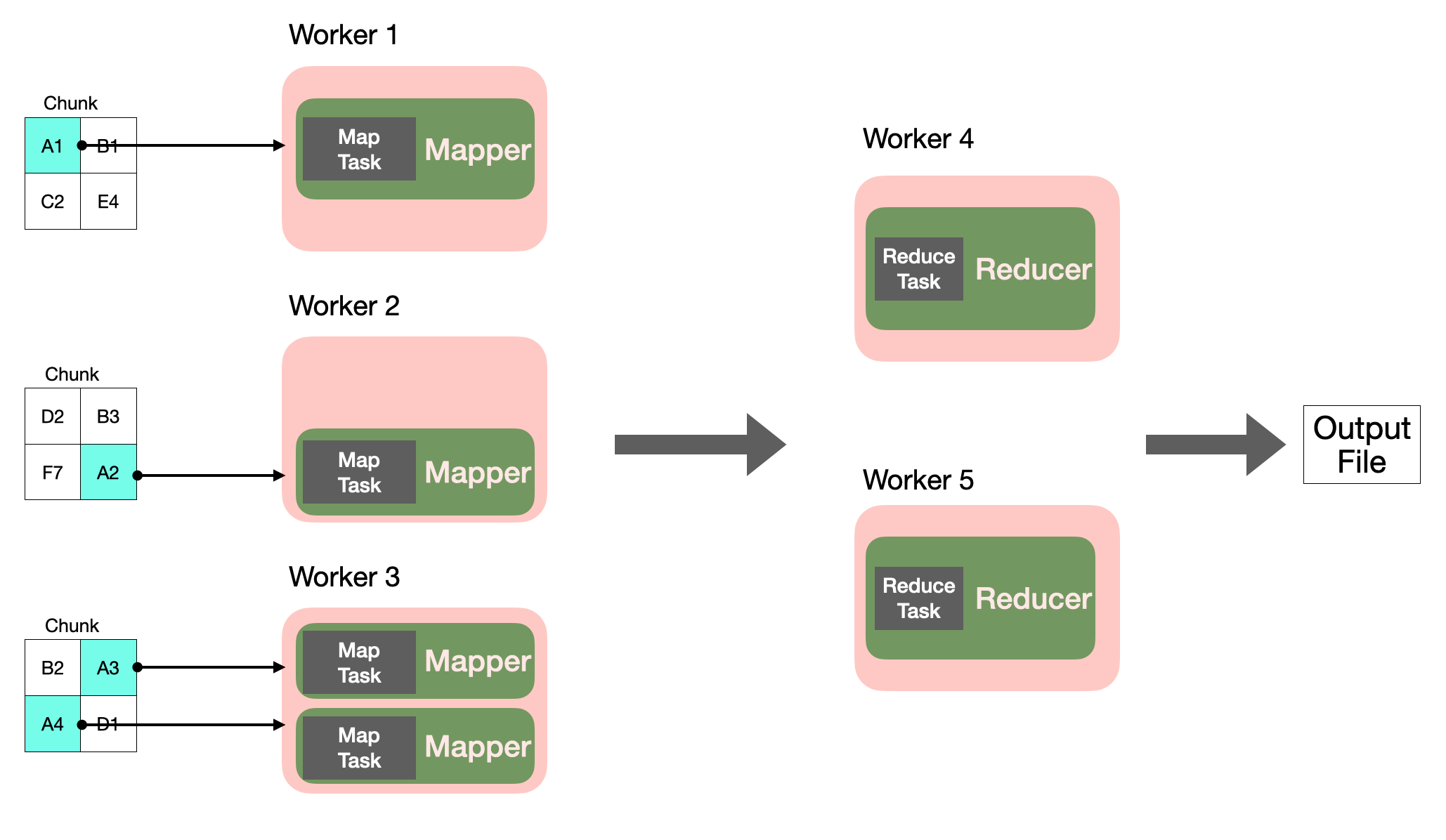
- Worker : 하나의 프로세스입니다. 노드 하나 당 하나의 프로세스가 수행됩니다. 하나 이상의 task 를 다룰 수 있습니다.
- Task : 더이상 나눌 수 없는 단위의 작업입니다.
- Map task : 하나의 입력(chunk)으로 Map function을 진행하는 작업입니다.
- Reduce task : 하나의 Reduce function 을 진행하는 작업입니다.
- Mapper : Map task 를 수행하는 프로세스 입니다.
- Reducer : Reduce task 를 수행하는 프로세스 입니다.
맵리듀스를 프로세스와 테스크 단위로 표현하면 다음과 같습니다.
Map
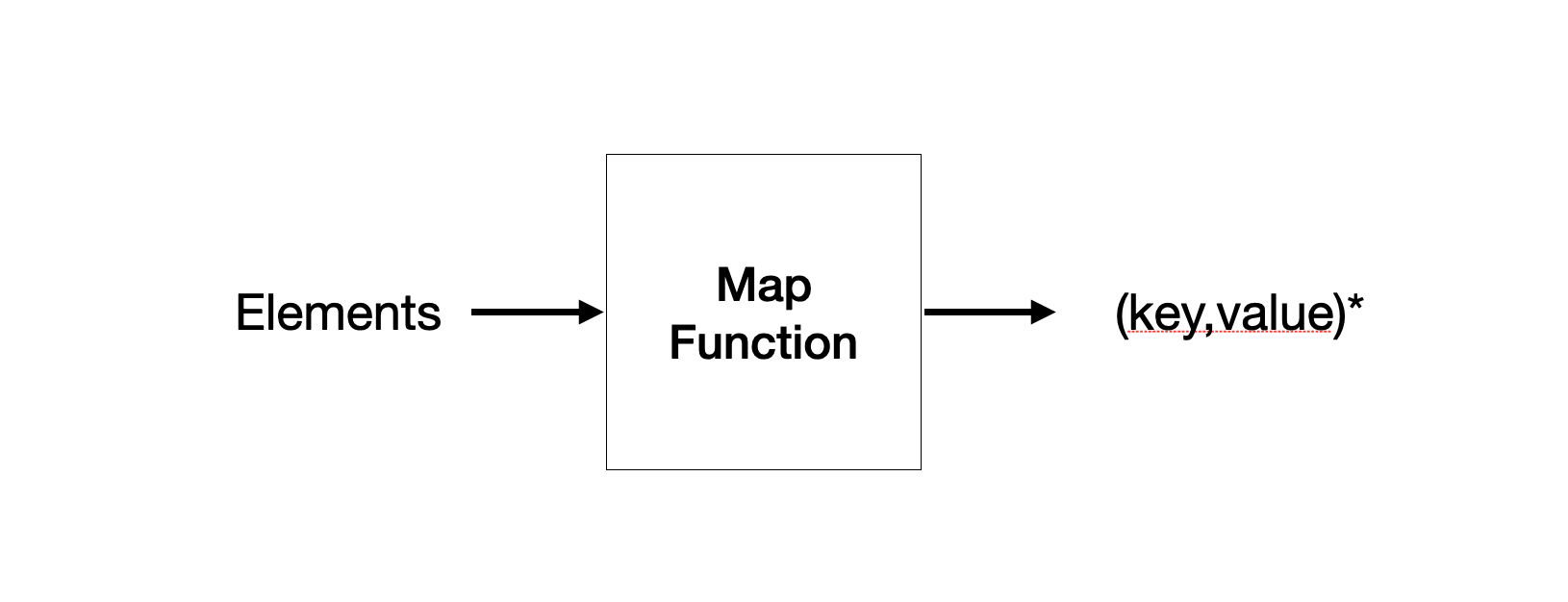
Map task 의 입력은 엘리먼트(=element) 들로 구성됩니다.
여기서 엘리먼트는 튜플이 될 수도 있고 문서가 될 수도 있습니다.
청크(=chunk)는 이 엘리먼트 들의 모음(=collection)이고, 엘리먼트가 두 개 이상의 청크에 걸쳐 저장될 수는 없습니다.
맵 함수는 이러한 청크, 즉,엘리먼트의 모음을 입력으로 받아 0 이상의 key-value 쌍을 출력합니다.
함수 내부의 동작은 사용자가 정의합니다.
입력을 받아 key-value 쌍을 출력하도록만 설정하면 됩니다.
타입 또한 임의로 설정할 수 있습니다.
(+ 여기서 key 는 일반적 의미의 key 와는 차이가 있습니다. key 이지만 unique 하지 않습니다. 동일한 key 로 여러개의 key-value 쌍을 만들 수 있습니다.)
Map task 의 예를 들어보겠습니다.
ex1 : 단어 빈도 수 세기 (word count)
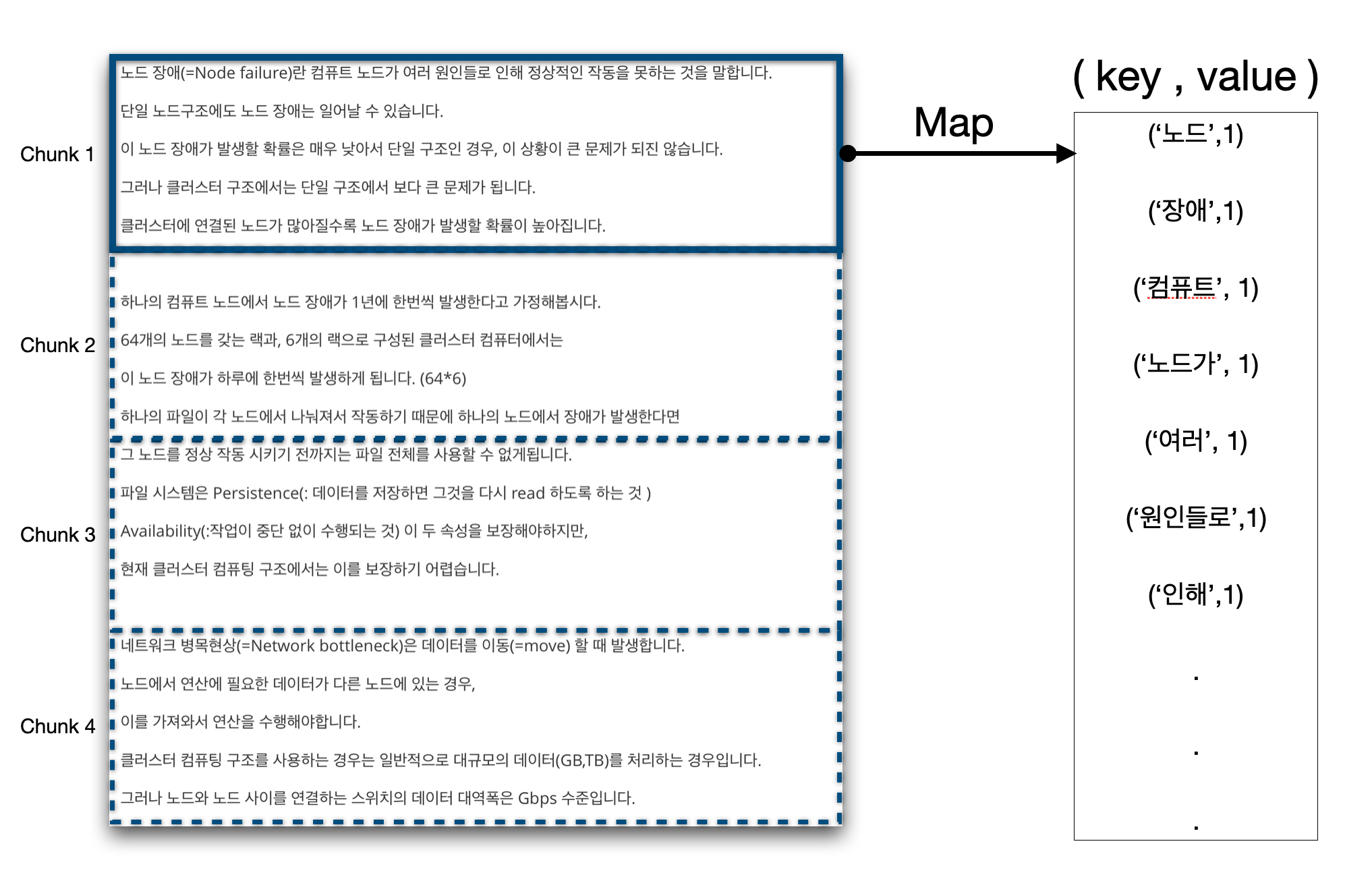
파일은 청크로 나눠집니다. 청크 하나 당 Map 함수가 수행됩니다.
문서를 읽고 단어들의 시퀀스로 나눕니다. 이 단어들은 key 가 됩니다.
$(w_1,w_2, … , w_n)$
여기서 key 의 value 는 1 입니다. 맵 단계에서는 현재의 key 에 대해서만 보게 됩니다. 각 key 를 count 하는 작업이므로 1이 됩니다.
ex2 : 항목 평균값 구하기
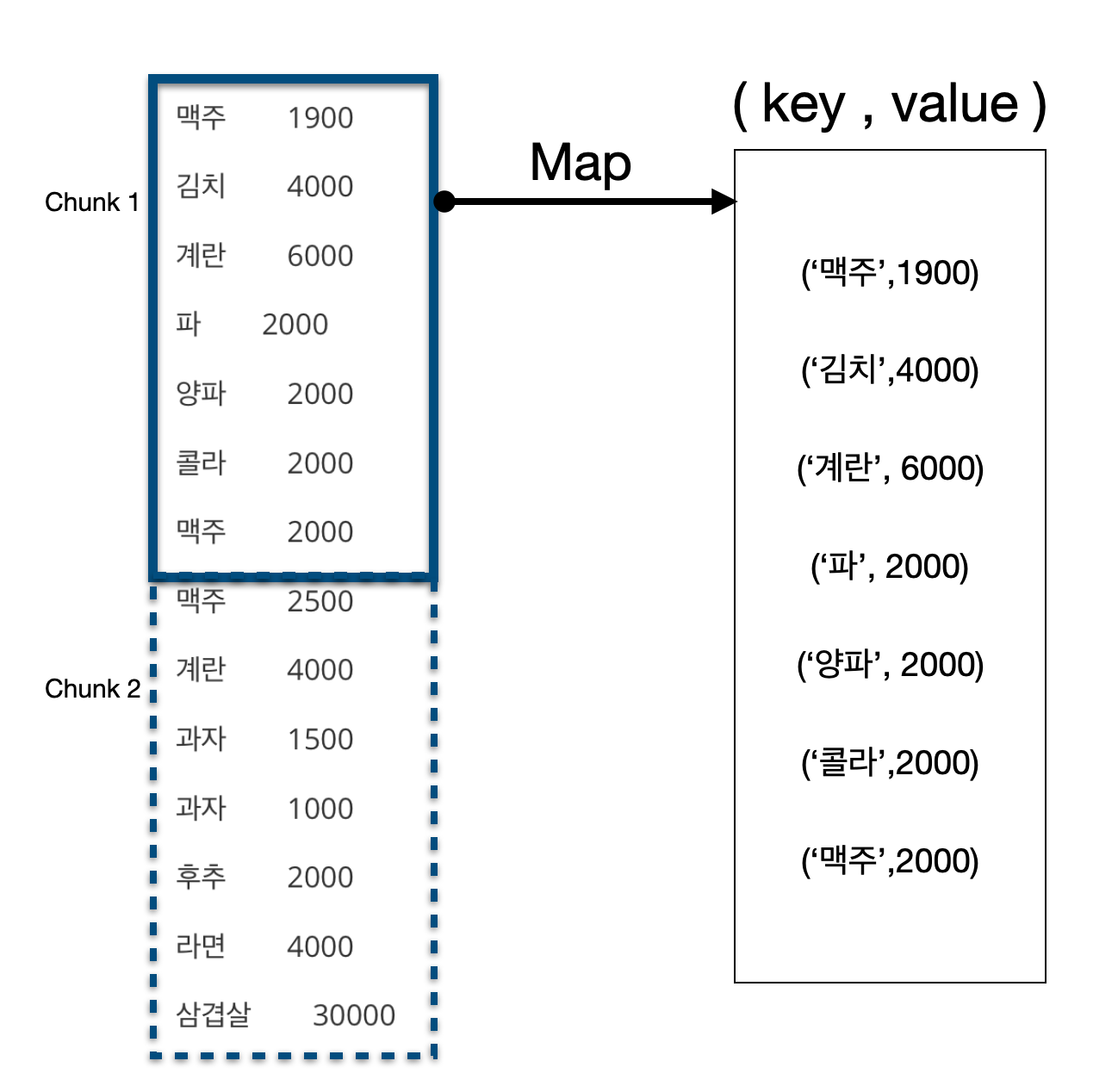
이 예시에서는 문자열을 key 로 갖고 그 옆의 정수를 value 로 갖습니다.
탭(\t)과 개행(\n) 문자를 기준으로 토큰을 자르고 key-value 쌍을 설정하면 됩니다.
Group by Key
Map task 가 완료되면 다음과 같이 key-value 쌍으로 묶임니다.
\[(k_1,v_a),(k_2,v_a),(k_3,v_b),(k_1,v_b),(k_1,v_c) ...\]여기서는 key-value 쌍들을 key-list 로 만들어 줍니다.
\[(k_1,[v_a,v_b,v_c]), (k_2,[v_a]), ...\]이 작업은 맵, 리듀스 작업과는 무관하게 진행됩니다. 사용자가 아닌 맵리듀스 시스템에 의해 수행되는 작업입니다.
이 단계에서는 Reduce task 에 분배하는 작업도 수행합니다.
전체 맵리듀스를 관리하는 Master controller process 는 몇개의 Reduce task 를 수행할지 알고 있습니다. (r 개의 task)
0부터 r-1 개의 버킷을 가진 해시 함수를 생성하고, Map task 의 출력이 hash 되어 r 개의 로컬 파일 중 하나로 들어가도록 만듭니다.
여기서 로컬 파일에는 key-value 쌍이 저장되어 있는 것이고
각 파일들은 r개의 Reduce task 중 하나의 입력으로 들어가게 됩니다.
입력으로 들어가기 전에 key-value 쌍들은 key-list 로 변환되어 Reduce 단계의 프로세스에게 제공됩니다.
ex1 : 단어 빈도 수 세기 (word count)
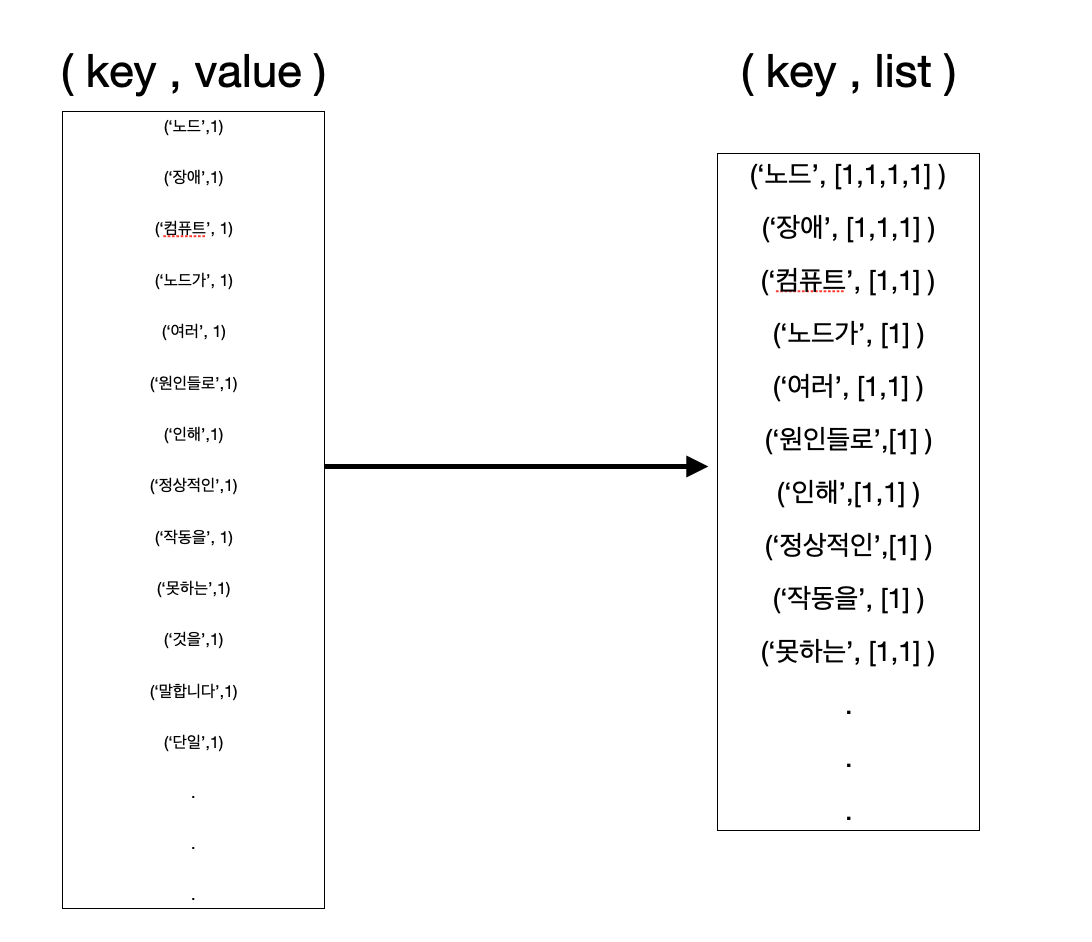
동일한 단어의 value 를 묶어서 리스트를 만듭니다.
ex2 : 항목 평균값 구하기
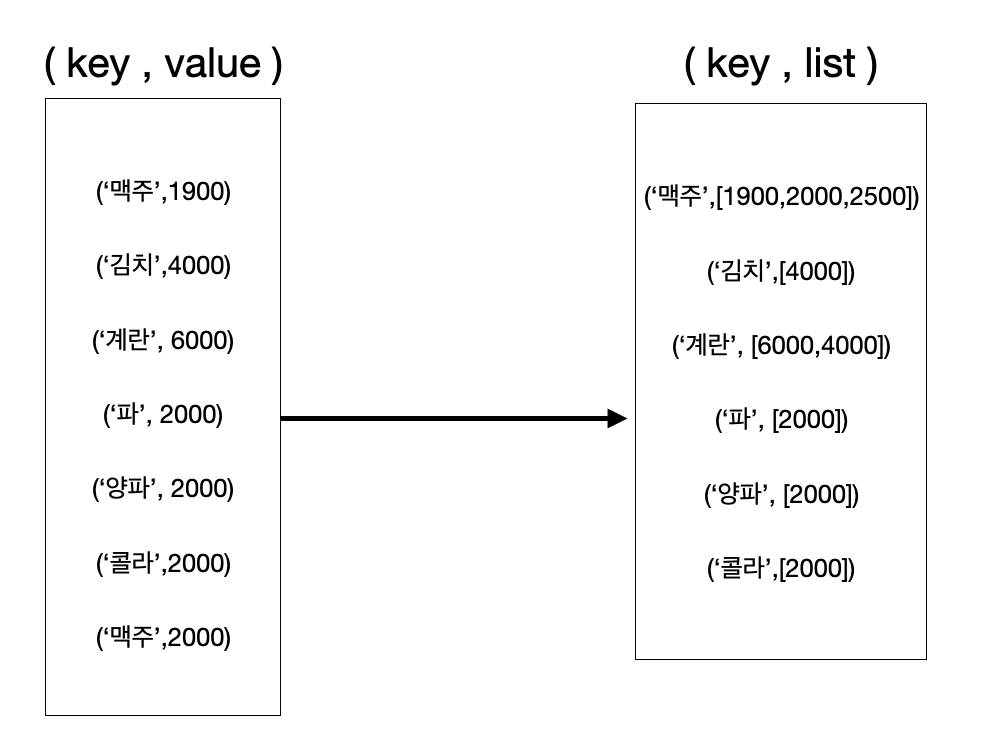
동일한 항목의 가격들로 구성된 리스트를 만듭니다.
Reduce
리듀스 함수의 입력은 key와 value 의 리스트로 구성된 하나의 쌍입니다.
함수의 출력은 0이 될 수도 있고, key-value 쌍이 될 수 있습니다.
사용자의 함수 구현에 따라 결과 값의 타입이 변경될 수 도 있습니다.
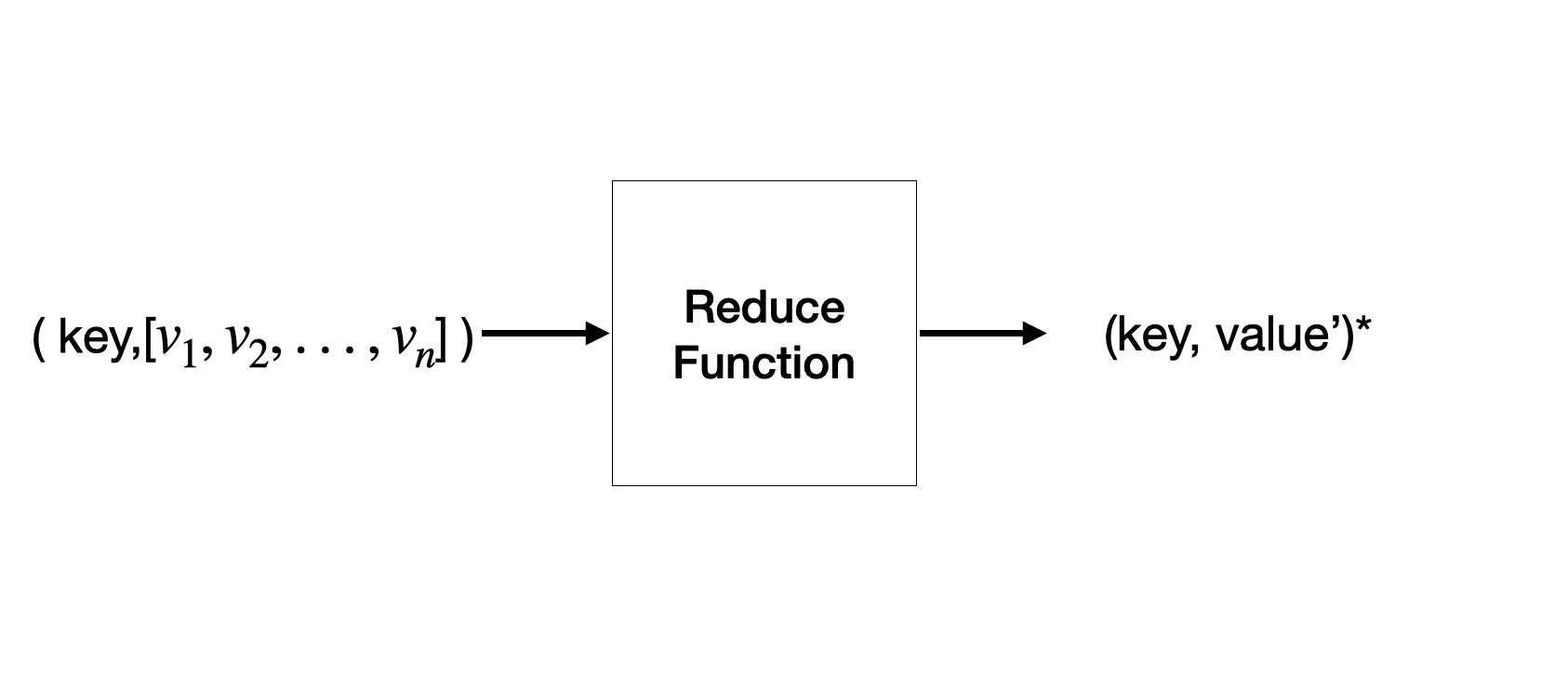
Reduce task는 하나 이상의 key-list 를 받습니다. Reduce task 안에는 여러개의 reducer(reduce 작업을 수행하는 process) 가 동작합니다.
이 리듀스 작업으로 부터 얻은 출력들은 하나의 파일로 합쳐져 저장됩니다.(DFS 형태)
ex1 : 단어 빈도 수 세기 (word count)
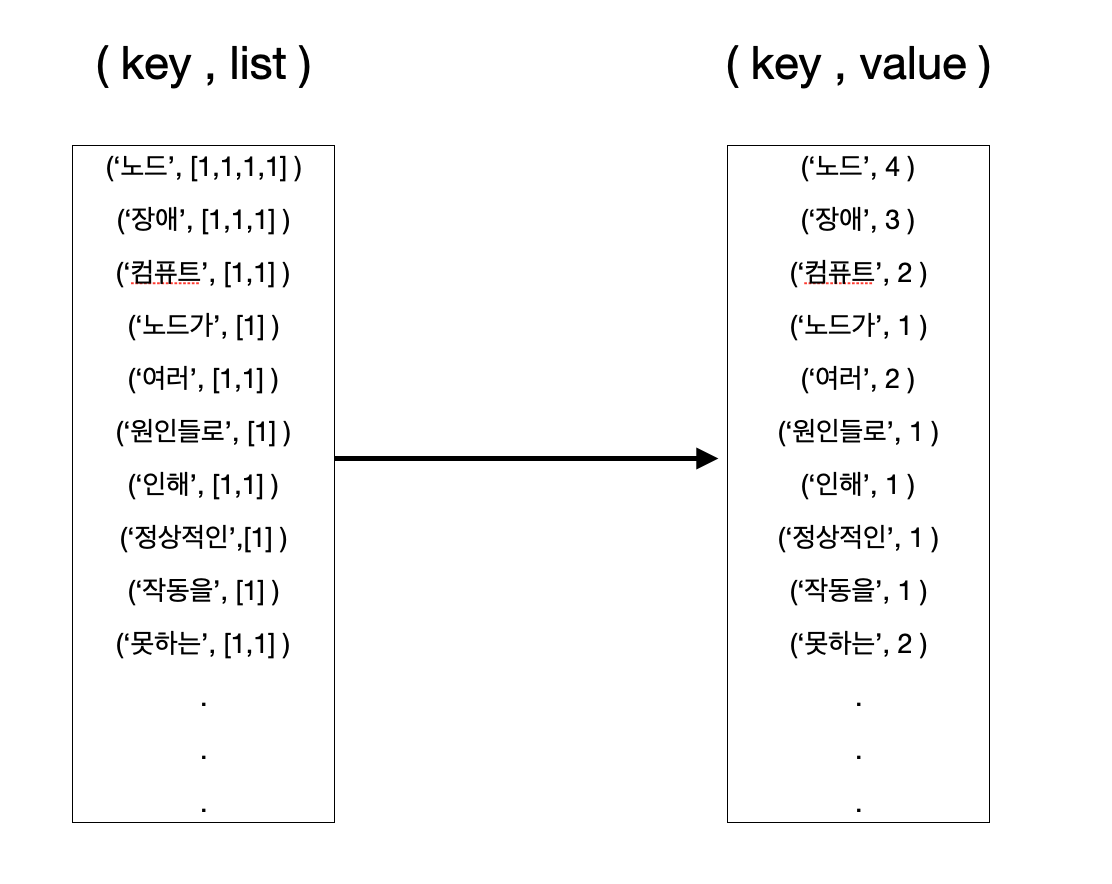
리스트의 각 항목의 합을 구합니다.
ex2 : 항목 평균값 구하기
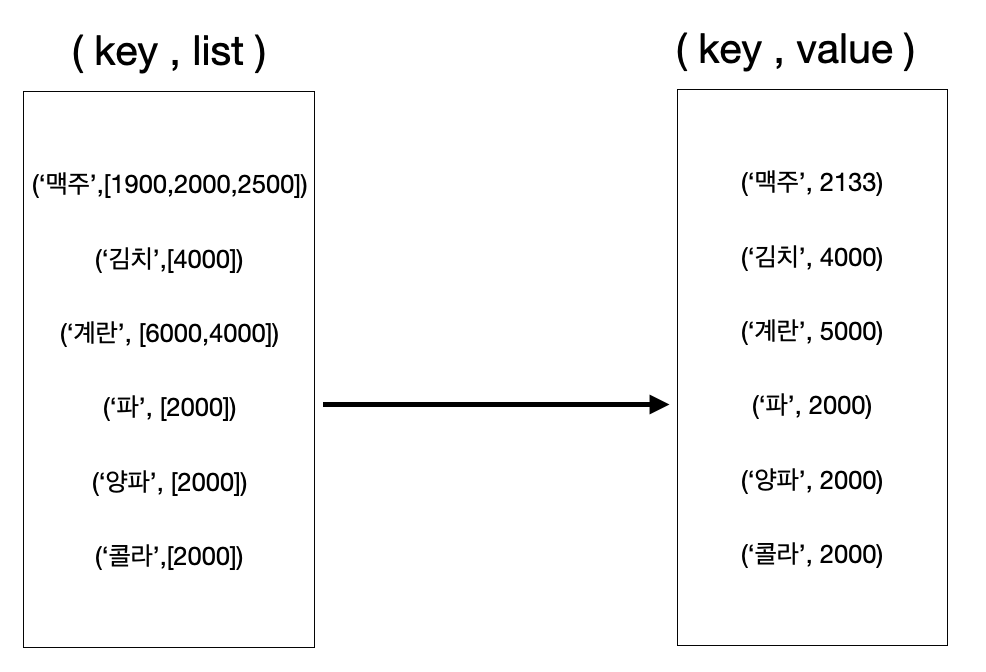
리스트의 각 항목은 가격을 나타내므로
항목들 간 평균을 냅니다.
전체 과정은 다음 그림과 같이 표현할 수 있습니다.
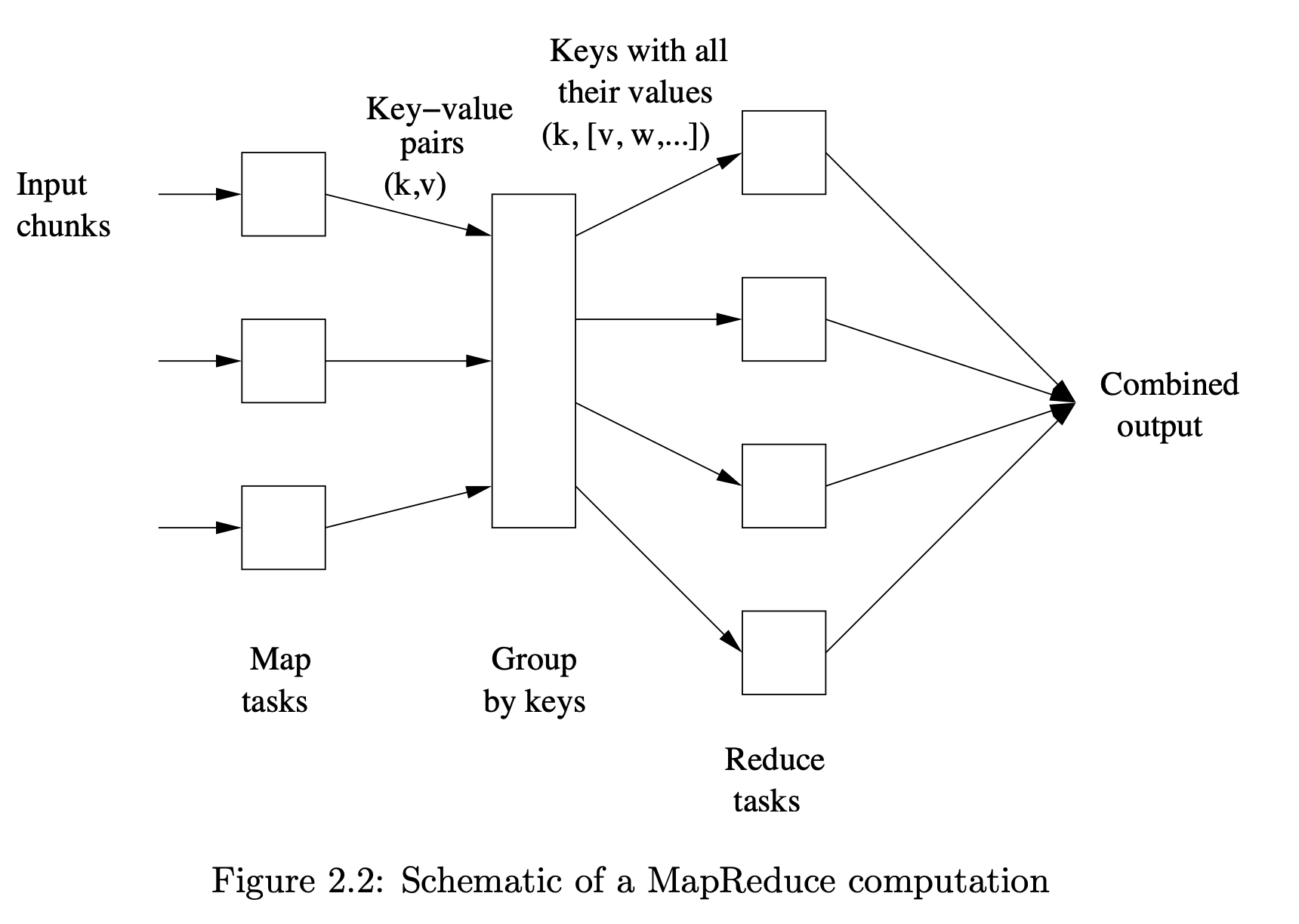
이미지 출처 : Mining of Massive Datasets - Figure 2.2
Map, Group, Reduce 3 단계를 순서대로 거쳐서 최종 결과가 출력됩니다.
입력은 chunk 로 부터 시작되어
key-value 쌍이 생성되고, value들을 묶어 list 로 합쳐줍니다.
key-list 는 Reduce 작업을 거친 후 파일 형태로 저장이 됩니다.
다음 포스팅에서는 MapReduce의 프로세서 단위에서의 동작과 Node failure 상황 대처 방법, 성능 향상 기법 등에 대해 다뤄보겠습니다.
Comments