Distributed File Systems
해당 포스팅은 스탠포드의 Anand Rajaraman 교수님의 강의 와 Mining of Massive Datasets(Jure Leskovec, Anand Rajaraman, Jeff Ullman) 책 을 참고하였습니다.
이전 포스팅에서는 대규모 데이터 처리를 위한 클러스터 컴퓨팅 구조에 대해 다뤘습니다.
컴퓨트 노드들을 이어서 병렬화 하는 구조에는 다음과 같은 3가지 문제가 발생합니다.
- Node failure
- Network bottleneck
- Programming
Node failure
노드 장애(=Node failure)란 노드가 여러 원인들로 인해 정상적인 작동을 못하는 것을 말합니다.
단일 노드구조에도 노드 장애는 일어날 수 있습니다.
이 노드 장애가 발생할 확률은 매우 낮아서 단일 노드인 경우, 이 상황이 큰 문제가 되진 않습니다.
그러나 클러스터 구조에서는 단일 구조에서 보다 큰 문제가 됩니다.
클러스터의 노드 중 하나만 장애가 발생하더라도 그 시스템은 중단됩니다.
때문에 클러스터에 연결된 노드가 많아질수록 노드 장애가 발생할 확률이 높아집니다.
하나의 컴퓨트 노드에서 노드 장애가 1년에 한번씩 발생한다고 가정해봅시다.
64개의 노드를 갖는, 6개의 랙으로 구성된 클러스터 컴퓨터에서는
이 노드 장애가 하루에 한번씩 발생하게 됩니다. ($64\times 6$)
하나의 파일이 각 노드에서 나눠져서 작동하기 때문에 하나의 노드에서 장애가 발생한다면
그 노드를 정상 작동 시키기 전까지는 파일 전체를 사용할 수 없게됩니다.
파일 시스템은 Persistence(: 데이터를 저장하면 그것을 다시 read 하도록 하는 것 )
Availability(:작업이 중단 없이 수행되는 것) 이 두 속성을 보장해야하지만,
현재 클러스터 컴퓨팅 구조에서는 이를 보장할 수 없습니다.
Network Bottleneck
네트워크 병목현상(=Network bottleneck)은 데이터를 이동(=move) 할 때 발생합니다.
노드에서 연산에 필요한 데이터가 다른 노드에 있는 경우,
이를 가져와서 연산을 수행해야합니다.
클러스터 컴퓨팅 구조를 사용하는 경우는 일반적으로 대규모의 데이터(GB,TB)를 처리하는 경우입니다.
그러나 노드와 노드 사이를 연결하는 스위치의 데이터 대역폭은 Gbps 수준입니다.
때문에 데이터를 전송하는데 스위치에서 병목현상이 발생하게 됩니다.
Programming
작업을 병렬적으로 처리하기 때문에 프로그램을 구현하는데 어려움이 있습니다.
공유자원에 대한 race condtion 이나 스케줄링 등 고려해야하는 상황이 많기 때문에 프로그래밍 자체가 어렵습니다.
이러한 문제들은 분산 파일 시스템(=Distributed File System - DFS) 과 맵리듀스(=MapReduce) 프로그래밍 시스템을 사용하여 해결 할 수 있습니다.
Distributed File System
DFS 는 일반적으로 다음과 같은 상황에서 사용하기 적합합니다.
- 파일들이 크기가 테라바이트 까지 클 수 있다.(작은 파일인 경우 DFS 를 사용하는 이점이 없습니다.)
- 파일 갱신(=update)은 드물게 일어나야한다. 연산을 위한 데이터로 읽히고(=read) 가능하다면, 새로 생기는 데이터는 파일에 추가(=append) 되어야 한다. 예를 들어 비행기 예약시스템과 같은 경우 데이터는 매우 크지만 빈번하게 바뀌기 때문에 DFS 에 적합하지 않습니다.
DFS에서 파일은 청크(=chunks)들로 나눠지고, 다음과 같이 다뤄집니다.
- 일반적으로 64MB 의 크기를 갖습니다.
- 청크는 여러개로 복제되어 다른 컴퓨트 노드들에 저장됩니다. 일반적으로 3개의 사본을 갖습니다.
- 일반적으로 사본의 청크는 다른 랙에 위치합니다. 그래서 rack failure 에도 파일이 손실되지 않습니다.
- 청크 크기와 사본의 수는 사용자가 결정 할 수 있습니다.
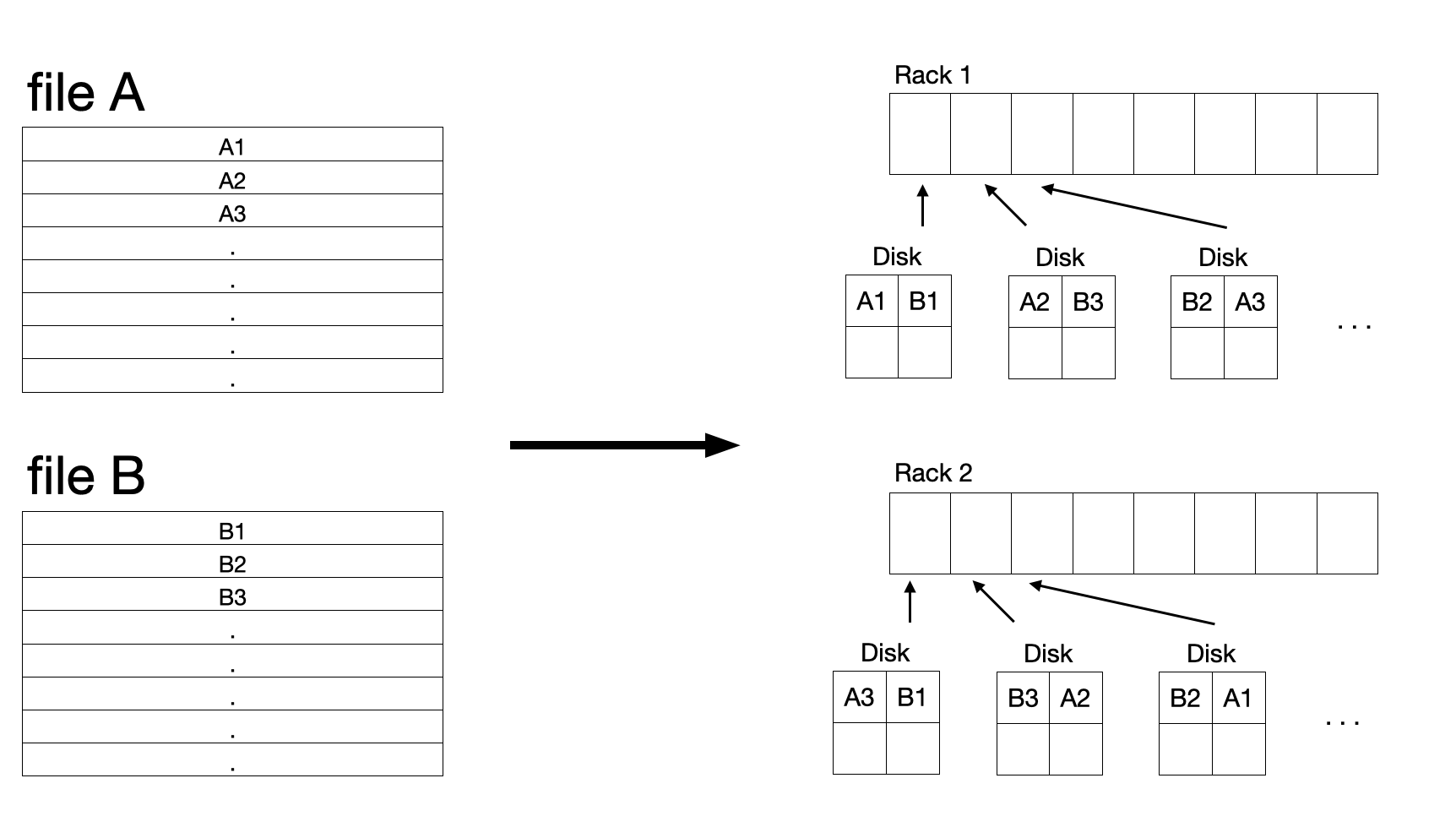
한 파일의 청크를 찾기 위해서는 마스터 노드(=master node, name node) 라고 불리는 작은 파일이 있어야 합니다.
마스터 노드는 파일 청크들와 사본들이 어디 있는 알려주는 디렉토리 역할을 합니다.
디렉토리는 복제되어 저장되고 DFS를 사용하는 모든 사용자들은 디렉토리 사본들이 어디있는지 알고 있습니다.
이렇게 파일을 나누고 복사하여 저장하는 방식으로 앞서 말한 Node failure 문제를 해결할 수 있습니다.
연산 중에 노드 장애가 발생하게 되면,
연산에 사용하던 청크의 사본이 있는 다른 노드를 사용합니다.
때문에 노드 장애가 발생하더라도 중단 없이 연산이 수행됩니다. (Availability)
또 특정 노드가 고장나서 해당 디스크의 데이터가 손실된다 하더라도
다른 노드에 동일한 데이터가 있기 때문에 Persistence 을 보장합니다.
이러한 파일 시스템을 도입하더라도
병목현상과 프로그램을 구현 난이도의 문제가 여전히 있습니다.
이를 해결하기위해 MapReduce를 사용합니다.
다음 포스팅에는 맵리듀스에 대해 다루겠습니다.
Comments