Cluster Computing Architecture
해당 포스팅은 스탠포드의 Anand Rajaraman 교수님의 강의 와 Mining of Massive Datasets(Jure Leskovec, Anand Rajaraman, Jeff Ullman) 책 을 참고하였습니다.
대부분의 계산(=Computation) 은 하나의 프로세서에서 수행됩니다.
디스크에 있는 데이터를 메모리로 가져와서 한번에 하나씩 처리합니다.
시대에 따라 데이터의 규모가 커지면서 이러한 수행 방식은 한계를 갖게 됩니다.
구글 웹 검색 엔진을 예로 들어 봅시다.
100억개의 웹 페이지가 있고, 웹 페이지 하나 당 20kB 로 간주한다면
한 번 검색을 수행할 때 200TB 의 데이터를 처리해야합니다.
CPU가 데이터를 디스크로부터 읽어 오는데에는 시간이 소요되고,
시간 당 데이터를 읽어 오는 양을 데이터 대역폭(=Data bandwidth) 라고 합니다.
이 대역폭을 50m/s (1초당 50MB) 이라 가정한다면,
웹 페이지 전부를 읽는데 46일 이상이 소요됩니다.
이렇게 기존 방식은 대규모 데이터를 처리하는데 있어 어려움이 있습니다.
이를 위한 대안으로 클러스터 컴퓨팅 (=Cluster computing) 이 제시 되었습니다.
클러스터 컴퓨팅은 여러대의 컴퓨터를 연결하여 작업들을 병렬적으로 처리하는 구조입니다.
클러스터 컴퓨팅으로 효율적인 병렬처리를 하기 위해서는
- 노드들을 이에 맞춰 구성해야하고(하드웨어 구성),
- 분산 파일 시스템(=distributed file system) 이 필요하며
- 이를 다루기 위한 맵리듀스(=MapReduce) 가 필요합니다.
위 순서대로 포스팅을 진행 할 계획이고,
이번 포스팅에서는 클러스터 컴퓨팅을 위한
하드웨어 구성에 대해 이야기해보자 합니다.
클러스터 컴퓨팅을 위한 컴퓨트 노드 구성
여기서 노드(=node)는 하나의 컴퓨터라고 보시면 됩니다.
클러스터 구조에서는 여러 노드를 사용하고,
노드의 역할에 따라 controller, network, compute 노드로 구분합니다.
병렬처리를 위한 클러스터 컴퓨터의 구조는 아래 그림과 같이 구성됩니다.
컴퓨트 노드는 랙(=Rack) 에 보관합니다.
하나의 랙에는 8에서 64개의 노드가 보관됩니다.
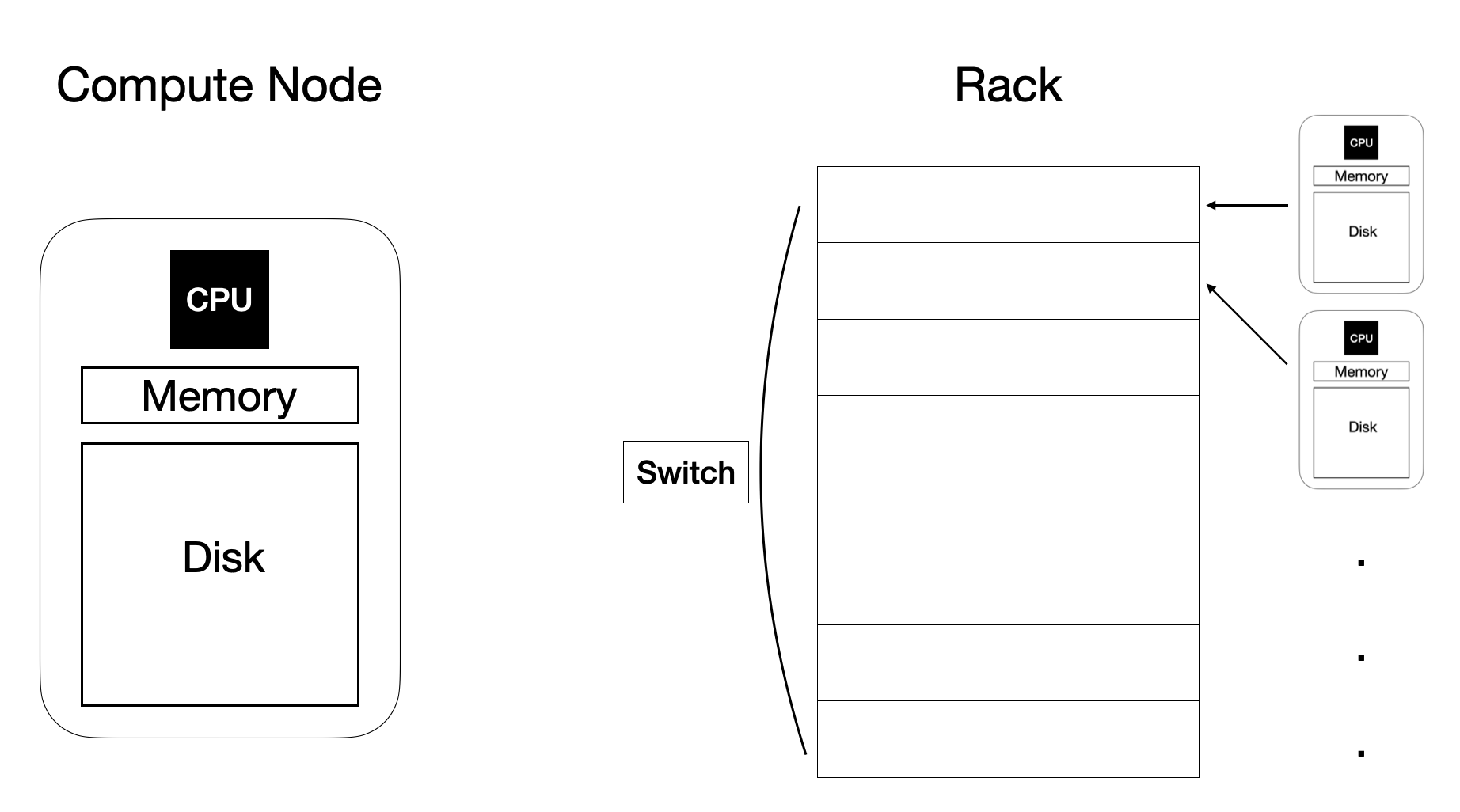
하나의 랙에 있는 노드들은 하나의 네트워크로 연결됩니다.
일반적으로 연결은 Gbps 통신이 가능한 이더넷(=Ethernet)으로 연결됩니다.
여러개의 노드가 연결된 랙은, 여러개가 있을 수 있고,
그 여러개의 랙들을 묶어 상위 레벨의 네트워크나 스위치로 연결합니다.
다음 그림과 같이 트리구조로 만들어집니다.
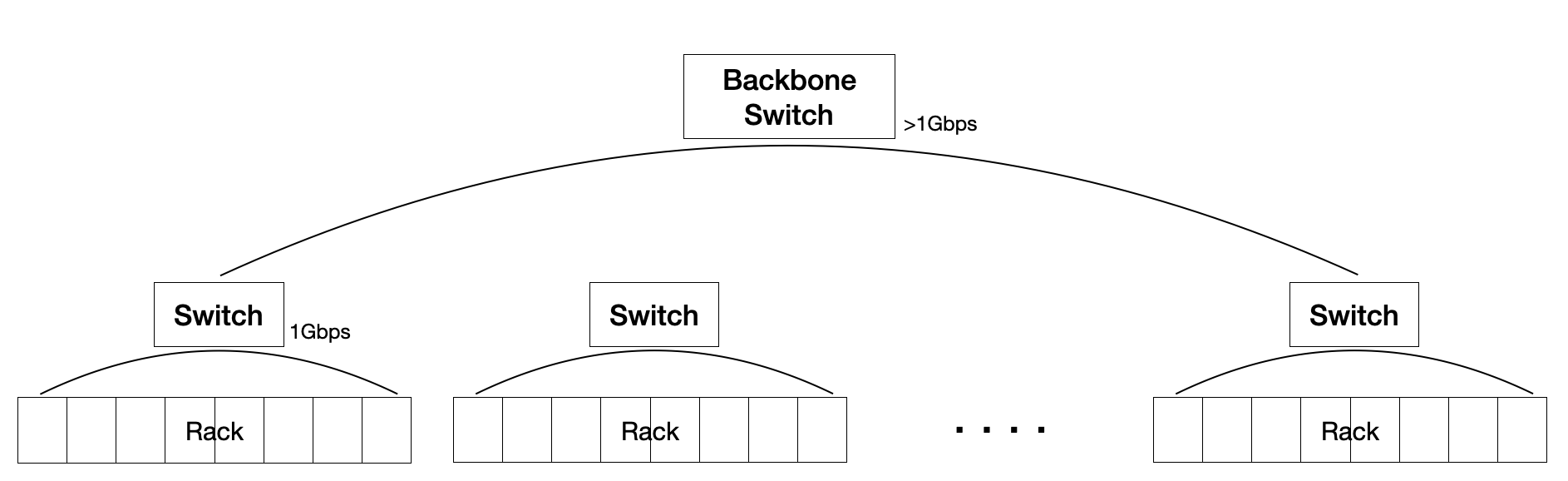
랙과 랙 사이(inter-rack) 데이터 대역폭은 랙 내부의 노드 간 이더넷의(intrarack) 대역폭 보다 더 높게 구성합니다.
다시 구글 웹 검색 엔진을 생각해 봅시다.
단일 컴퓨트 노드로는 200TB 의 데이터를 처리하기 위해서 46일 이상이 소요되었습니다.
예를 들어 64개의 컴퓨트 노드가 있는 랙을 64개를 사용한다고 가정하면 (\(2^{12}\)),
46일이 걸리는 작업을 1000초 이내로 수행할 수 있게 됩니다.
이렇게 컴퓨트 노드들을 연결하면 병렬 계산이 가능해집니다.
그러나 단순하게 연결만 하는 방법으로는 여러 문제들이 발생하게되는데,
이를 해결하기 위해서는 분산 파일 시스템과 맵리듀스가 필요합니다.
다음 포스팅에는 클러스터링 시 발생하는 문제들과
그에 따른 해결 방식 중 하나인 분산 파일 시스템에 대해 다뤄보겠습니다.
Comments